Social Network Analysis (SNA) – Architecture
The Social Network Analysis architecture has two major aspects:
The Analysis Data Management collects the transactional data from the system that manages the Social Network, like an Enterprise 2.0 system, a discussion group management system or other systems that manage production data from which a Social Network can be extracted. Famous systems are Facebook or LinkedIn, however, those systems do not allow the access to their complete Social Network or the extraction thereof. In addition, the Analysis Data Management establishes a consistent data set (usually in specified intervals) for the analytics computation. This ensures that all analytics computation is based on the same data set for consistency. Finally, it manages the results of the analytics computation and makes them available to the software that provides access to the analytics results for users or analysts.
The Analytics Computation is the set of all analytics queries (algorithms) that are executed on a consistent data set. These algorithms can be of various types, can run quickly or take up significant time, and independent as well as dependent on each other (to avoid re-computation of already available data).
Performing Analytics Computation in regular intervals is the most common approach due to the amount of data and the length of the processing computing time required. Computing analytics queries on user access with low latency is not realistic in the general case. However, in specific circumstances, it might be feasible to execute some analysis algorithm on user access dynamically. In this case, however, it must be clear to the user that the data set used for instantaneous computation might be different from the last periodic analytics computation execution. It is possible that in this case discrepancies exist when the data set evolved enough to have certain results be different.
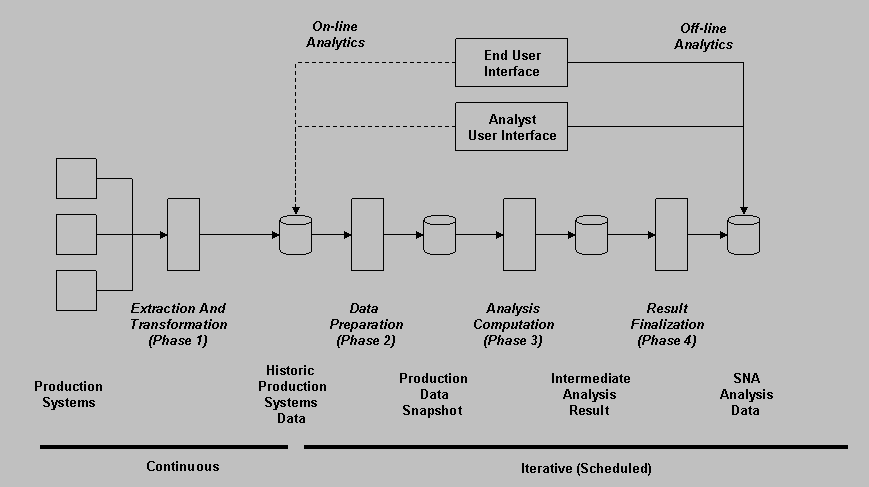
The Social Network Analysis architecture consists of several interacting components. These are shown in the following figure. The various phases and modes of analytics are introduced afterwards.
Social Network Analysis is performed on historical transactional data coming from production systems, like Social Network systems or Enterprise 2.0 systems. The data managed by these systems (e.g., social relationships, user accounts, ratings, blogs, wikis, etc.) is changing constantly and the amount of data is usually increasing. The data of the production systems are the source for the Social Network Analysis (and in general there can be more than on production system that feeds data into the Social Network Analysis system).
The overall execution life cycle of Social Network Analysis (SNA) starts with collecting the data updates coming from production systems:
Phase 2, 3 and 4 are iterative and are repeated many times. One possible strategy is to create snapshots by the data preparation phase on a fixed schedule (like once a day), or on a "as soon as possible" strategy. In principle, as soon as a snapshot is prepared, another one can be prepared in parallel, and consequently the analysis execution phase can be run in parallel, too. The schedule and degree of parallelization is determined by the needs of the company. However, the available space for data and the available computational power must be increased significantly in case of parallelism.
The final SNA Analysis Data produced by Phase 4 is being replaced with the result of each subsequent scheduled execution so that end users and analysts always operate on the latest data set.
Traditionally analytics is performed on historic data, meaning, a snapshot of the production data or the historic data up to a point in time was basis for analytics. This resulted in "off-line" analytics where the result of the analytics queries are on a data set that is not completely actual as compared to the transactional data of the production systems. However, in Social Network Analysis, this is not necessarily the only appropriate strategy due to the user behavior.
Users, when for example adding a friend relationship, immediately afterwards want to check how their network reach increased. In this use case it does not make sense to compute the network reach off-line as the user would have to wait until the analytics execution phase. Instead, users demand "on-line" analytics that is performed on the actual state of the production data set.
Therefore it is very important to distinguish the modes of analysis:
For each Social Network Analytics query it must be decided, if the query is available in off-line mode or on-line mode (or both). This has an implication of the necessary computational power as well as storage space available.
The technology deployed was changed during the course of the project. There were two phases:
In the initial phase a stack of Semantic Technologies was used. It was comprised of a semantic database, SPARQL and a development environment specialized for modeling semantic structures and SPARQL queries on RDF and RDF/S.
The network data were represented as RDF triples and transferred over from a transaction system. The network analysis was implemented as a series of SPARQL queries in the semantic database. The result was made available as various types of graphs that were incorporated into the transaction system.
The second phase re-implemented the social network analysis algorithms based on a relational database management system. The network data were in relational form in the transaction system. While the semantic technologies provided a strong support for the functionality, the technology integration in order to integrate the semantic technologies was considered to be too costly. The results from phase 1 were therefore transferred over to the existing relational technology stack.
In context Social Network Analysis, interesting research questions can be asked:
© Christoph Bussler